起因
最近在研究 V8 引擎的過程中,突然很好奇我平常在 javascript 裡面實作的sort 演算法是如何,所以讓我找到了 Timsort 這個十分神奇的演算法,而這個演算法同時也是 python 還有 android platform 實現 sort 的演算法。

上面這張圖是我在蒐集 Timsort 資料時找到的表,從上圖可以看出來 Timsort 的表現相對其他的 sort 演算法是相當優秀的,眼睛細一點的人可能會發現 Heapsort 的表現也相當好,但是他是一個不穩定的演算法(這裡科普一下排序穩定與不穩定的差別,他們的差別在於當今天有兩個相同的數在做排列時,排列完後會不會調換位置,如果會那就是不穩定的,反之則是穩定的)。那在我正式介紹 Timsort 之前,請讀者先複習一下 Insertion sort 與 Merge sort,因為這兩個 sort 是構成 Timsort 的基礎,底下就當作讀者已經了解上述那兩個 sort 了。
Timsort原理
首先讀者們應該都明白在長度不大的序列裡,Insertion sort 的表現非常好,所以 Tim 將長度小於 64 的序列,使用 Insertion sort 做排序。因此我們接下來處理的都是長度大於 64 的序列,而要介紹 Timsort 必須分成兩步來處理,第一步是切割,第二步是合併,我們一步一步來說明。
切割
Tim 認為在現實世界中的序列大多都是已經部分排序的(partial sorted)
所以在第一步是從序列的左到右開始尋找非嚴格遞增或是嚴格遞減(為了符合stable)的序列,舉個例子(我不可能舉長度超過64的序列所以示意而已):
{ 3, 5, 9, 11, 7, 3, 4, 6, 8, 9, 20 }
我們可以將上面那個序列拆開變成
{3, 5, 9, 11}{7, 3}{4, 6, 8, 9, 20}
而這些被拆開的序列我們將他稱之為 一個 run,像上面的序列總共就有三個 run,那如果今天恰好很不幸這些 run 的長度都很短,總不能每兩三個就切一個run吧,這樣合併的時候會花太多步驟,所以這裡必須定義一個minrun,假設現在minrun = 3,套用剛剛的例子,上面那個序列就會被切成
{3, 5, 9, 11}{7, 3, 4}{6, 8, 9, 20}
如果切完後長度大於 minrun,那就沒事繼續往下切,如果長度小於 minrun,就必須補齊長度到 minrun,之後的步驟就是將遞減的序列翻轉,若是 run 有被補元素進去,那就用 Insertion sort 將該個 run 排序好,像是上面的例子:
{3, 5, 9, 11}{3, 7, 4}{6, 8, 9, 20} - 遞減的翻轉
{3, 5, 9, 11}{3, 4, 7}{6, 8, 9, 20} - Insertion sort 排序
那問題來了,該如何知道這個 minrun 的值是多少呀?這個 minrun 必須滿足三個條件,
- 必須小於 64 ,因為大於 64 的 Insertion sort 效率會變差。
- 盡可能的平均分配,不能有全部都剛好是 minrun 而最後一個只剩下很少元素的情況發生
- 盡可能將切割完的 run 的數量控制在二的次方,方便待會的Merge sort
因此 Tim 想了一個非常聰明的方法,先將序列的總長度表示成二進位,取出前六個數之後如果後面還有值,就+1,舉個例子:如果總長度是197,換成二進位那就是 11000101,取出前六個數 110001 = 49,後面還有 01 所以將49+1=50,那麼在最壞的情況下,會被拆成 50 50 50 47,剛好滿足了上面的那三個條件,這個方法真的相當聰明。以上我們已經將 Timsort 的切割完全介紹完畢。
休息一下我們繼續來看合併
合併
為了達到高效率且省空間的合併,Tim 精心設計了合併的細節,先聊大方向的合併,我們手上現在有非常多個 run,我們從最右邊抓三個 run 出來,由左到右依次命名為 runX, runY, runZ,只要不滿足以下兩個條件的其中之一,就將 runY 與 ( runX 和 runZ 較小的 )合併:
- runX > runY + runZ
- runY > runZ
至於為什麼是這個方式呢?考慮到每次合併的 run 的大小必須盡量相同,這麼做可以最大化達成這項目的。
接下來我們來聊兩個 run 之間的合併,為了解決 Merge sort 在處理空間上的不足(可以往上回去看第一張圖),Tim 想出了底下的合併方法:

- 將比較小的 run 當成圖中的 X
- 把 runX 複製到一個新的空間 temporary
- 接下來用 Merge sort 合併
上面這個合併的方法可以確保在最壞的情況下,Timsort 使用的空間是 n/2 (Tim真的是個很務實的人),到這邊其實已經可以算是很圓滿的結束了,但是 Tim 覺得這樣不行,還必須對 Merge sort 做出優化,所以 Tim 提出了 Galloping mode。
Galloping
再強調一次!
Tim 認為在現實世界中的序列大多都是已經部分排序的(partial sorted)
所以假設有兩個序列 {1, 2, 3, 4, 5, …,1000} {2001, 2002, 2003, …,3000}做 Merge sort,總共需要比對一千次,這實在是太耗資源了,所以 Tim 想了一個新的做法,就是只比二的次方的數,比完之後再用 binary search(前面已經排序好了) 找到那個對的位子,這樣總共比較的次數可以壓低到 O(logn),但是Tim又發現了一個問題:
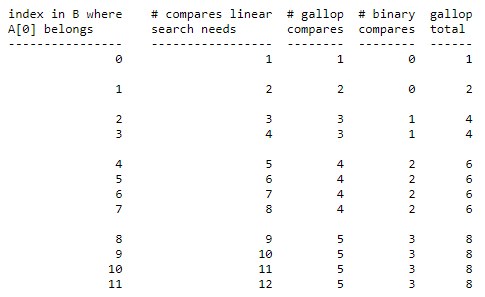
從上面那張圖可以發現在比較 2, 4 的時候 linear search 的效果是比 galloping 的效果來的好的(分別是左二欄和右一欄),所以 Tim 決定當兩個序列比較到第七次都是由同一個序列取值時,才啟動 Galloping mode。以上就是 Timsort 所有合併的細節了。
結語
之所以會寫這篇文章實在是苦於沒有足夠清楚的文章在闡述 Timsort 所有的細節和為什麼要做這些決定,讓我去翻了他的原文找原因,不過也讓我發現了 Tim 的這些細節都為這個演算法加分了不少,所以才配用他的名字來命名。這是筆者第一次寫文章,有任何問題都可以反應給我,謝謝看到最後!
參考文件:
